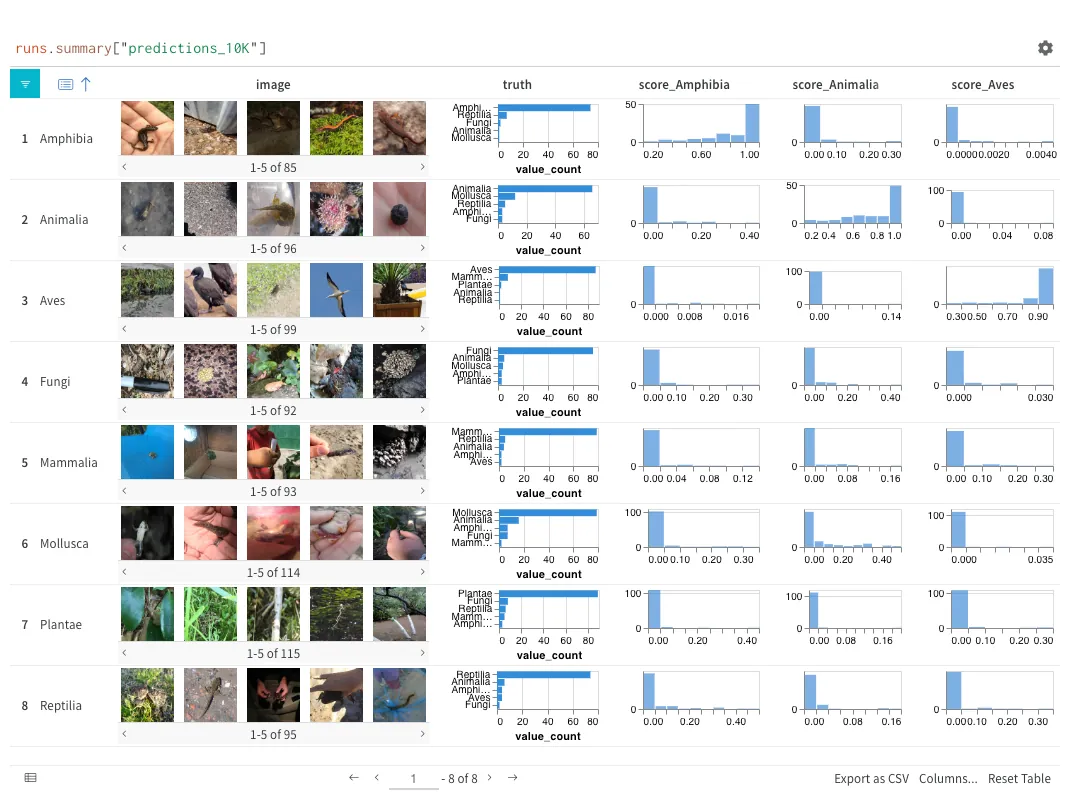
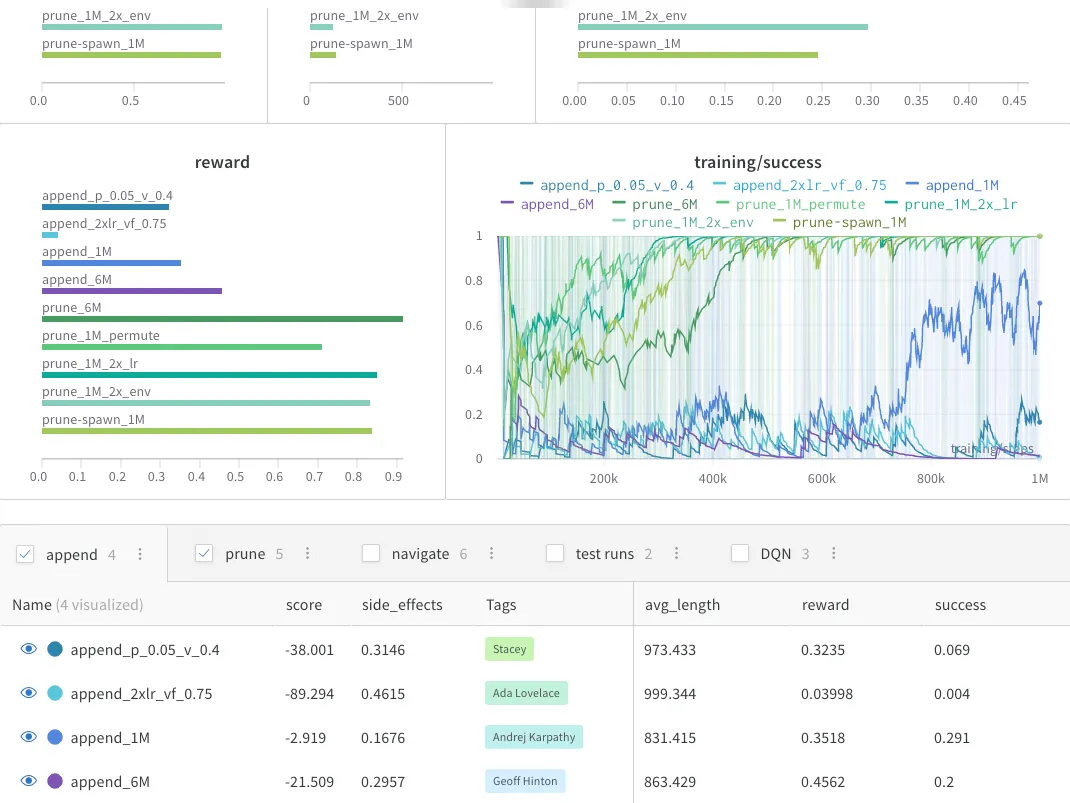
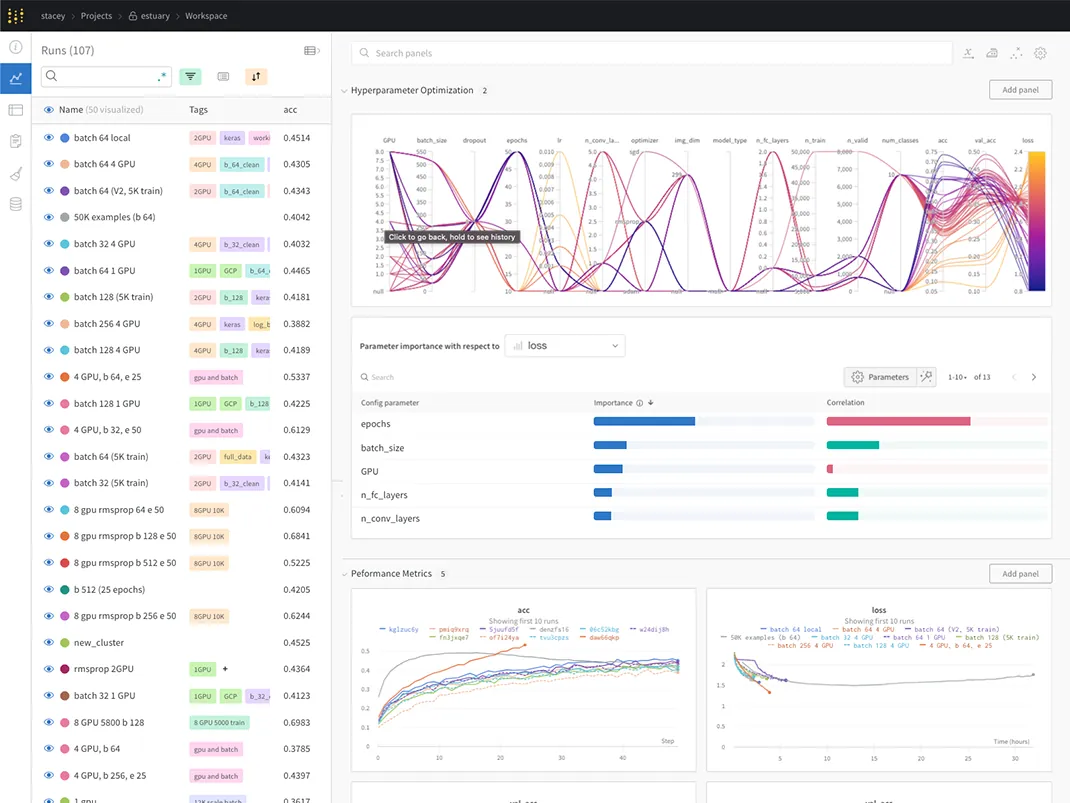
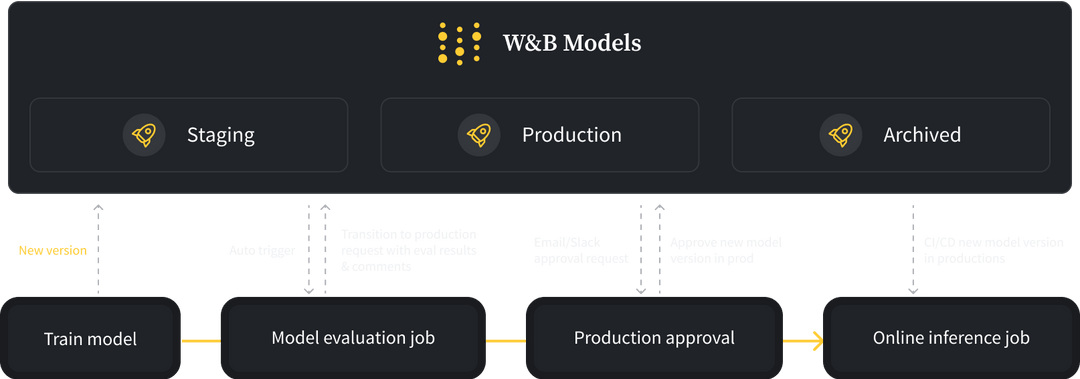
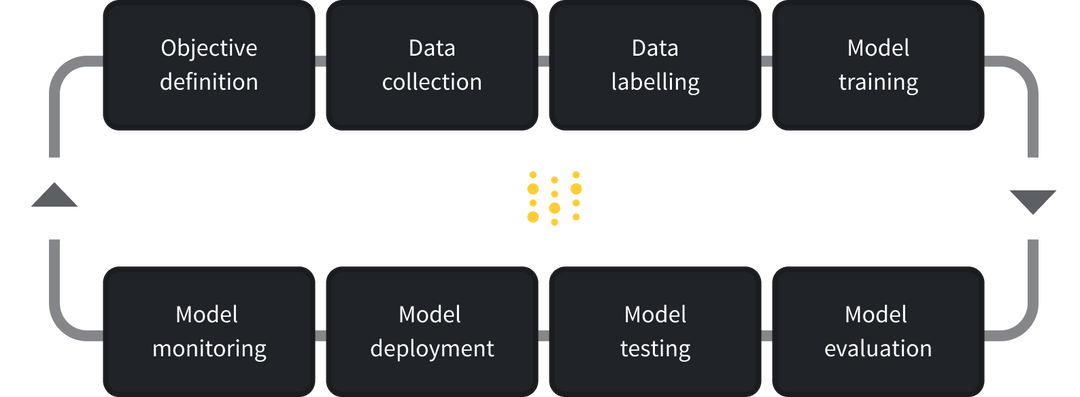
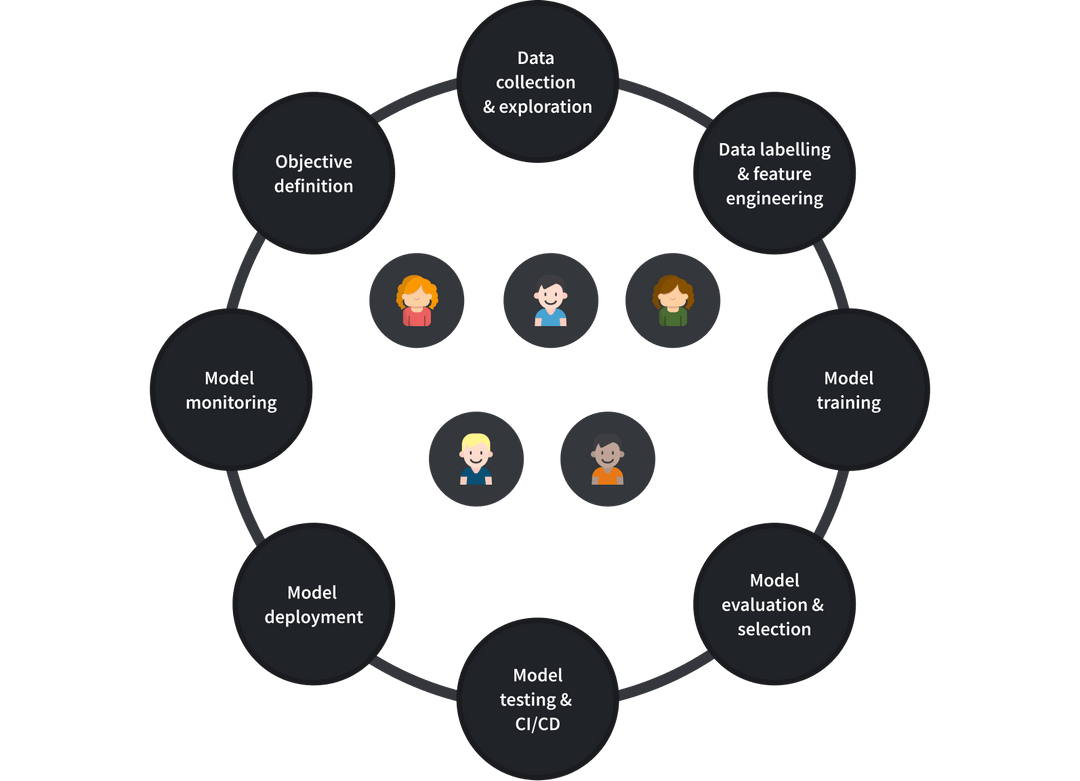
Experiments
Track and visualize your ML experiments
Sweeps
Optimize your
hyperparameters
Launch
Package and run your
ML workflow jobs
Model Registry
Register and manage
your ML models
Automations
Trigger workflows
automatically

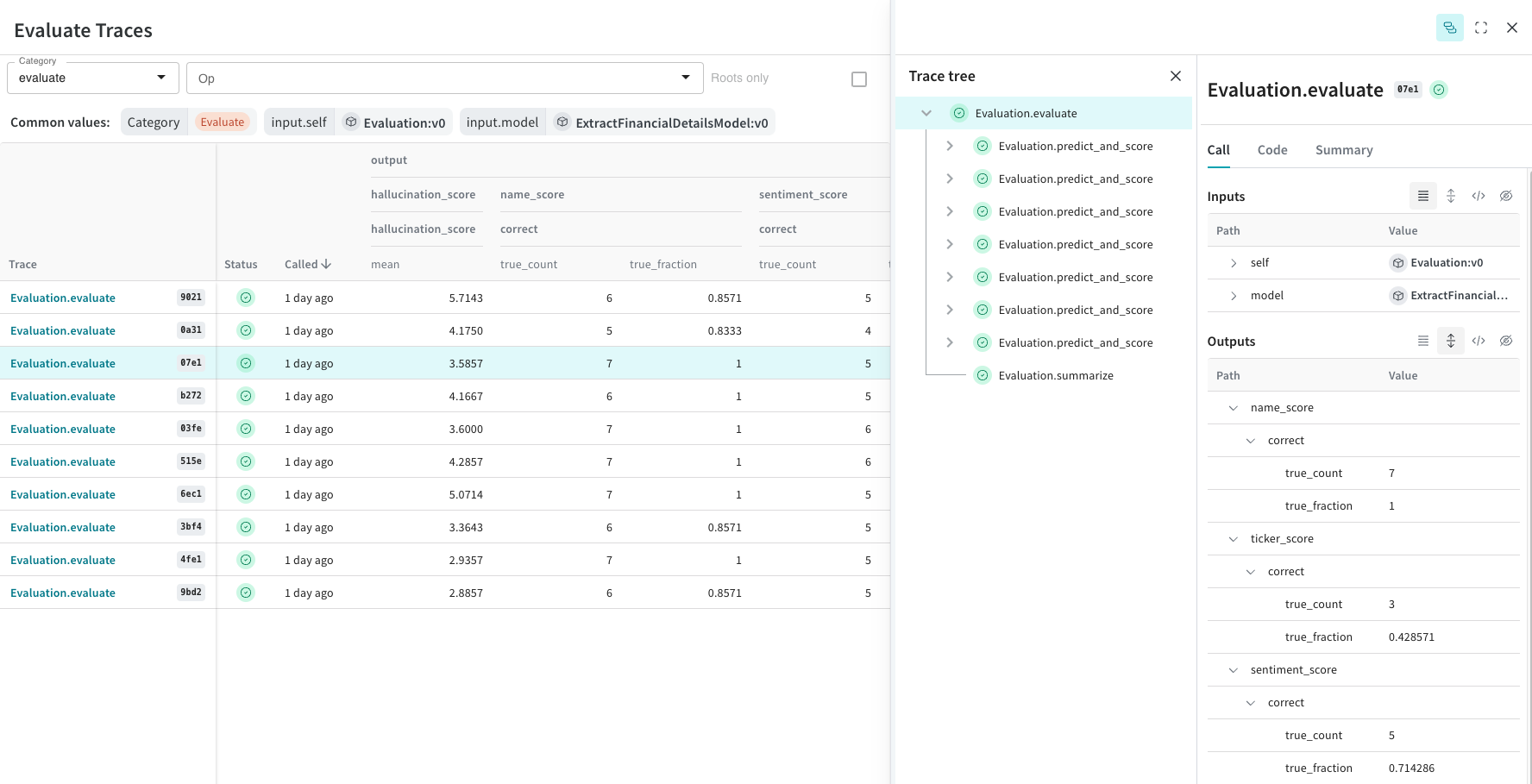
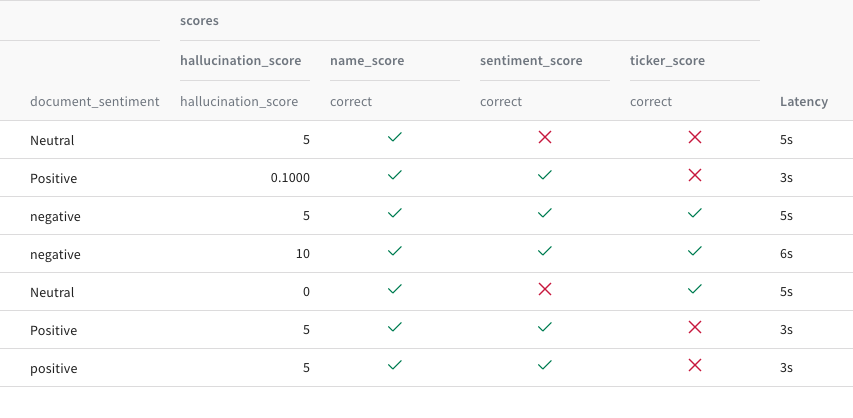
Traces
Monitor and debug
LLMs and prompts
Evaluations
Rigorous evaluations
of GenAI applications